#Install usual data science libraries
!pip install numpy scipy matplotlib scikit-learn pandas rdkit seaborn plotly
#Install tmap
!pip install tmap-viz
#Download ESOL dataset
!mkdir data/
!wget https://raw.githubusercontent.com/schwallergroup/ai4chem_course/main/notebooks/04%20-%20Unsupervised%20Learning/data/esol.csv -O data/esol.csv10 Week 4 tutorial 1 - AI 4 Chemistry
![]()
Table of content
- Unsupervised learning: dimensionality reduction
- PCA
- t-SNE
- TMAP
0. Relevant packages
Scikit-learn
We will use again the scikit-learn package, which contains the PCA and TSNE methods that we will implement.
TMAP
TMAP is a powerful visualization method capable of representing high-dimensional datasets as a 2D-tree. It can be applied in different domains apart from Chemistry. If you want to know more, you can check the original paper.
We first install the necessary libraries and get the corresponding dataset
1. - Dimensionality reduction
Dimensionality reduction is a fundamental concept in unsupervised learning that aims to reduce the number of features or variables in high-dimensional datasets while preserving the most relevant information. This technique is particularly relevant when dealing with large and complex datasets with a high number of features in common. Besides, it can help scientists to better understand the underlying structure and relationships in their data. Here are some of the most common methods in dimensionality reduction:
- PCA (Principal Component Analysis)
- t-SNE (t-distributed Stochastic Neighbor Embedding)
- NMF (Non-Negative Matrix Factorization)
- UMAP (Uniform Manifold Approximation and Projection)By reducing the dimensionality of the data, it is also possible to visualize and interpret the data more easily, and to develop more efficient and accurate predictive models. In this notebook we will explore some dimensionality reduction methods.
2. PCA
PCA (Principal Component Analysis) is a popular unsupervised learning technique used for dimensionality reduction. It aims to transform high-dimensional data into a lower-dimensional space while preserving the most important information by identifying the principal components of the data. PCA is widely used in data analysis, visualization, and feature extraction.
Exercise 1: ESOL dataset dimensionality reduction with PCA
In this exercise, we will apply PCA to the 2048-dimensional fingerprints representing the molecules in the ESOL dataset. We will try to reduce this space to 2 dimensions and plot the resulting space. Normally, before applying PCA you have to standardize your data, but in this case it is not necessary as we use binary features.
import pandas as pd
from rdkit import Chem
from rdkit.Chem import AllChem
from rdkit.Chem import PandasTools
import numpy as np
#Load ESOL
esol = pd.read_csv('data/esol.csv')
### YOUR CODE #####
#Create a 'Molecule' column containing rdkit.Mol from each molecule
#Create Morgan fingerprints (r=2, nBits=2048) from Molecule column using apply()
####
esol.head()Now, we apply the PCA decomposition. You can check the documentation of the method here.
from sklearn.decomposition import PCA
#### YOUR CODE ####
#create PCA object with n=2
#Create a numpy array containing the fingerprints
#Apply the fit_transform method to the previous array and store it in coordinates
#Add PC1 and PC2 values to each row
####Let’s plot the data using PC1 and PC2
import seaborn as sns
import matplotlib.pyplot as plt
sns.scatterplot(data=esol, x='PC1', y='PC2')
plt.title('ESOL PCA plot');Finally, we will create a special category of labels to add to this plot. The labels will represent solubility categories. For the sake of simplicity, we will create 3 categories:
- Low: log solubility lower than -5
- Medium: log solubility between -5 and -1
- High: log solubility higher than -1The only purpose of this classification is adding more information to the plot, so you can explore different interpretations of the reduced space you are representing.
#Create function to add labels
def solubility_class(log_sol):
'''Return the corresponding label according to solubility value
'''
if log_sol < -5:
return 'Low'
elif log_sol > -1:
return 'High'
else:
return 'Medium'
### YOUR CODE ####
#Add labels to the ESOL dataset by applying the previous function
#Create the PCA plot again including the new labels
#####
plt.title('ESOL PCA plot with solubility label');As you can see, the label categories are quite mixed, and the plot do not clearly show a trend in our data. However, you may keep trying different visualizations (for example, you could add another dimension to the plot by including the PC3 and try to see if a 3D representation gives more information).
3. t-SNE
t-distributed Stochastic Neighbor Embedding (t-SNE). In contrast to PCA, t-SNE is able to separate nonlinear data, and it can be therefore more powerful to capture local structures and identify clusters of data points with similar features. However, it is computationally more expensive than PCA and it may not be suitable for very large datasets.
Exercise 2: ESOL dataset dimensionality reduction with t-SNE
In the following example, we will apply t-SNE to the previous dataset and compare the result to PCA decomposition. You can check the documentation here
from sklearn.manifold import TSNE
### YOUR CODE ####
#Create a tsne object with n_components=2 and random_state=42. The latter parameter is used to ensure
#reproducibility (this is a non-deterministic algorithm)
#get the fp array
#apply fit_transform() to the data
#create columns with the tSNE coordinates in the original df
#####Now, plot the results including the solubility label and compare them to the PCA plot. Do you observe differences between the algorithms?
### YOUR CODE ####
####
plt.title('ESOL t-SNE plot');4. TMAP
Finally, we will use TMAP for visualizing our solubility dataset. A TMAP plot is constructed in 4 phases:
1. LSH forest indexing: data are indexed in an LSH forest data structure
2. kNN Graph Generation: data are clustered using a c-approximate kNN graph
3. MST Computation: a Minimum Spanning Tree is calculated
4. Layout generation of the MSTThe corresponding representation displays the data as a tree in 2D, showing the relationships between the different points not only through the presence of clusters but also through the branches of the tree.
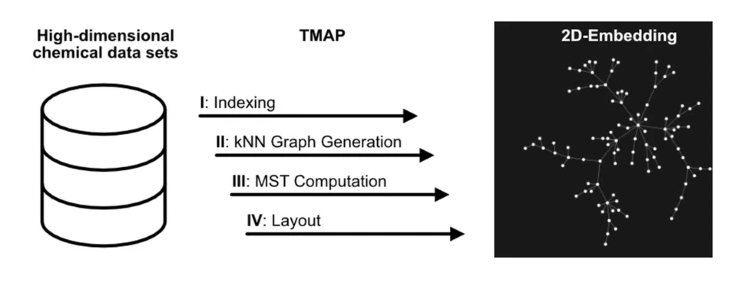
Below we show how to create a simple visualization of our data via TMAP.
import tmap as tm
#get fingerprints of molecules
fps = esol['fp'].values
#Transform fingerprints into tmap vectors
vec_fp = [tm.VectorUchar(fp) for fp in fps]
#Create MinHash encoder and LSH Forest
enc = tm.Minhash(512)
lf = tm.LSHForest(512, 128)
#add vec_fp to minhash encoder and then pass it to the LSH forest
lf.batch_add(enc.batch_from_binary_array(vec_fp))
lf.index()
# Configuration for the tmap layout
CFG = tm.LayoutConfiguration()
CFG.node_size = 1 / 50
#Compute graph
x, y, s, t, _ = tm.layout_from_lsh_forest(lf, CFG)Once you have computed the graph, you can plot it. In our case, we use matplotlib.
#Create figure
fig, ax = plt.subplots(figsize=(12,12))
#Create a class to convert solubility class to integers
def solubility_class_to_int(log_sol):
'''Return the corresponding label according to solubility value
'''
if log_sol < -5:
return 0
elif log_sol > -1:
return 1
else:
return 2
#apply previous function (we create an array that will be used in the plotting function)
esol['int_class'] = esol['log solubility (mol/L)'].apply(solubility_class_to_int)
#Plot edges
for i in range(len(s)):
plt.plot(
[x[s[i]], x[t[i]]],
[y[s[i]], y[t[i]]],
"k-",
linewidth=0.5,
alpha=0.5,
zorder=1,
)
#Plot the vertices
scatter = ax.scatter(x, y, c=esol['int_class'].values, cmap='Set1', s=2, zorder=2)
plt.tight_layout()
classes = ['High', 'Medium', 'Low']
plt.legend(handles=scatter.legend_elements()[0], labels=classes)
plt.title('ESOL TMAP visualization')
plt.plot()Alternatively, you can use other libraries like plotly or Faerun to plot the data in a more interactive mode.
#example using plotly
import plotly.express as px
fig = px.scatter(x=x, y=y, color=esol['sol_class'].values,
hover_name=esol['smiles'].values, color_continuous_scale=['#FF0000','#4169E1','#2E8B57'], title='ESOL TMAP')
fig.show()We recommend you to check the original repo to observe the different possibilities of applying TMAP. Cheers to Daniel Probst for creating this great tool!